
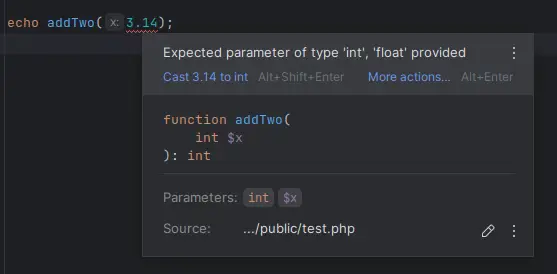
Powyższy fragment kodu jest przypadkiem bardziej skomplikowanym. O niepoprawnym typie danych poinformuje nas już IDE, a jeśli mimo wszystko nie zauważymy ostrzeżenia, to aplikacja zwróci błąd 500 w przypadku niepoprawnego typu danych.
Co się stanie, jeżeli nie pilnujemy typów?
Przełóżmy nasze proste przykłady na bardziej realistyczny przypadek. Załóżmy, że pracujemy nad systemem e-commerce. Podstawą e-commerce są produkty. Produkt musi mieć swoją cenę (nie ważne czy zapisaną bezpośrednio w modelu produktu, czy też w innym modelu powiązanym).
Cenę produktu najbezpieczniej jest przechowywać jako liczbę całkowitą (czyli w postaci groszy). Dlaczego? Bo liczby całkowite lepiej zachowują się chociażby przy wyliczaniu rabatów. Ale to już temat na inny wpis.
Przy projekcie pracuje kilku programistów. W organizacji nie ma zasady stosowania ścisłej kontroli typów. Jeden z developerów przygotował klasę modelu (encję). Użył typowania, przygotował setter do ceny. Setter przyjmuje liczbę całkowitą. Inny programista był odpowiedzialny za przygotowanie panelu administracyjnego. Wiadomo, — człowiekowi wygodniej pracuje się na cenach złożonych z pełnych złotówek i groszy. Niestety developer nie sprawdził, jak w modelu zapisywana jest cena. Założył, że, tak jak w jego poprzedniej organizacji, jest przechowywana jako pole DECIMAL w bazie danych. W związku z czym nie wdrożył konwersji ze złotówek na grosze. Kod trafił na code review i nikt nie wykrył błędu. Po wgraniu na środowisko testowe okazało się, że występuje spory problem. W panelu administracyjnym zostaje wpisana cena 123,00 zł, a na frontendzie wyświetla się cena 1,23 zł. Jak do tego doszło? Setter „wyciął” część dziesiętną ceny i zapisał liczbę całkowitą do bazy danych. Frontend odebrał cenę w groszach, czyli 123 grosze. Po przeliczeniu dało to cenę 1,23 zł. A wystarczyło tylko dodać kontrolę typów. Interpreter od razu poinformowałby o problemie.
#5 Nie wymyślaj koła na nowo — używaj gotowych bibliotek
Wydaje się to oczywiste, a jednak w wielu projektach utrzymaniowych spotkałem się z customowym rozwiązywaniem dobrze znanych problemów.
Dlaczego tak się dzieje?
Wielu młodych programistów chce „pokazać, że umie”. Z tego powodu w swoich projektach tworzą customowe rozwiązania. I to nie rozwiązania dotyczące specyficznej logiki biznesowej rozwiązującej problemy klienta. Piszą setki linii kodu, które można by rozwiązać użyciem biblioteki i jednej linijki kodu.
Dlaczego jest to problemem?
Gotowe biblioteki mają rozbudowaną społeczność developerów, którzy z nich korzystają, a także tych, którzy je rozwijają. Jeżeli paczka jest popularna, a dodatkowo stale rozwijana, możemy mieć pewność, że zastosowane w niej mechanizmy są zdecydowanie bardziej wydajne od tych, które wypracujemy sami. W końcu żaden programista nie jest całą społecznością!
Kolejny problem to aktualizacje. Jeżeli komunikujemy się z jakimś interfejsem API, to możemy być pewni, że będzie on się zmieniał w przyszłości. Takie zmiany mogą zmusić programistów do wprowadzania ogromnych zmian w kodzie. W przypadku gotowych bibliotek najczęściej mamy zapewnioną kompatybilność wsteczną, więc może się okazać, że jedyna zmiana, którą musimy wykonać, to aktualizacja biblioteki. To bardzo wygodne rozwiązanie.
Jakie jeszcze mogą być zagrożenia wynikające z nieużywania bibliotek?
Tutaj chciałbym posłużyć się przykładem, który można spotkać w praktycznie każdej aplikacji. Tym przykładem będzie resetowanie hasła.
Jak działa przykładowy flow?
- Użytkownik klika przycisk „Nie pamiętam hasła”.
- Użytkownik podaje adres e-mail, na który ma założone konto.
- System generuje wiadomość e-mail z linkiem do resetu hasła.
- Użytkownik ustawia nowe hasło.
Przypadek bardzo prosty, a jednak trzeba pamiętać o kilku rzeczach „po drodze”:
- Musimy zadbać o to, żeby nie zdradzić czy konto o podanym adresie e-mail istnieje, czy nie (czyli zwracamy sukces za każdym razem).
- Musimy zadbać o unikalność linku do resetu hasła.
- Musimy zadbać o odpowiedni czas wygaśnięcia linku.
- Powinniśmy ukryć token resetu w adresie URL (czyli np. zapisać go w sesji i przekierować użytkownika).
- Powinniśmy ograniczyć ilość możliwych zapytań o reset hasła dla danego użytkownika w ciągu określonego czasu.
Zapewne znalazłoby się jeszcze kilka punktów, które mógłbym dopisać.
Prosta funkcjonalność, a im dłużej się o niej myśli, tym więcej znajduje się potencjalnych problemów związanych między innymi z zabezpieczeniami.
A wystarczy użyć biblioteki, na przykład SymfonyCasts/ResetPasswordBundle.
Czy przy użyciu bibliotek musimy na coś uważać?
Zdecydowanie tak!
Pierwszą rzeczą, na którą musimy zwrócić uwagę jest licencja. Zanim użyjemy biblioteki powinniśmy ją dokładnie przeczytać. Nie chcemy przecież doprowadzić do sytuacji, w której nasz komercyjny produkt stanie się darmowy, ponieważ załączyliśmy w nim bibliotekę opartą na licencji, która sprawia, że cały produkt staje się wolnym oprogramowaniem.
Kolejna rzecz to popularność biblioteki. Kiedy przeglądamy kartę biblioteki w repozytorium pakietów (jakim jest np. Packagist) możemy zobaczyć ilość instalacji paczki. Im więcej instalacji, tym paczka bardziej popularna, a co za tym idzie sprawdzona przez społeczność.
Warto również sprawdzić ilość problemów security czy otwarte issues w repozytorium biblioteki.
Co jeśli nie używamy bibliotek?
Tak na prawdę utrudniamy życie sobie lub innym developerom, którzy będą utrzymywać naszą aplikację.
Jak zawsze najlepiej pokazać to na przykładzie. Niech będzie nim wdrożenie systemu płatności w sklepie internetowym. Klient zdecydował się na wdrożenie bramki płatności XYZ. Bramka dostarcza pakiet SDK dla języka PHP oraz pełną dokumentację REST API. Jako programista decydujesz się wdrożyć własne rozwiązanie oparte na REST API. Aplikacja została wydana, klient zadowolony. Po pół roku dzwoni telefon — „Panie nie działa. Co mi pan sprzedał?”. Sprawdzacie aplikację — błąd 500. No ale jak to? Przecież działało. Sprawdzacie dokumentację REST API — nastąpiła wielka zmiana. Całkowicie zmieniła się struktura request i response. Co teraz? Siadacie i kodujecie rozwiązanie na nowo. Kilka godzin pracy jak nic.
A jak by to wyglądało, gdybyście użyli SDK? Pewnie skończyłoby się na aktualizacji biblioteki. To zdecydowanie szybsze rozwiązanie.
Oczywiście ten przykład jest wyolbrzymiony. Żadna bramka płatności nie zrobi breaking changes swojego API w ciągu pół roku. Ale podobne sytuacje można znaleźć również w innego typu aplikacjach.
Podsumowanie
Budowanie aplikacji przy użyciu Symfony PHP wymaga nie tylko znajomości frameworka, ale także stosowania dobrych praktyk, które zapewniają jakość, bezpieczeństwo i łatwość utrzymania kodu. Korzystanie z wersji LTS, pisanie testów, analiza kodu, silne typowanie oraz używanie gotowych bibliotek znacząco minimalizują ryzyko błędów i skracają czas rozwoju aplikacji. Ignorowanie tych zasad może prowadzić do problemów z aktualizacjami, spadku wydajności i wzrostu kosztów utrzymania. Warto pamiętać, że oprócz tych zasad, zawsze należy stosować się również do oficjalnych zaleceń zawartych w dokumentacji Symfony framework, w szczególności w sekcji Best Practices.














